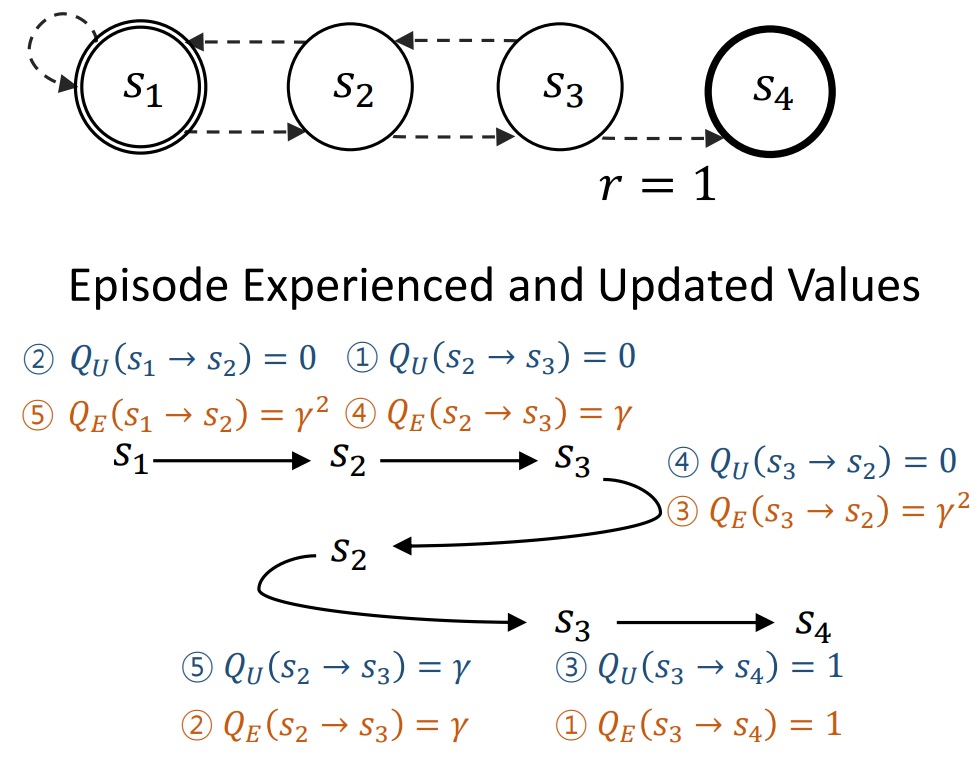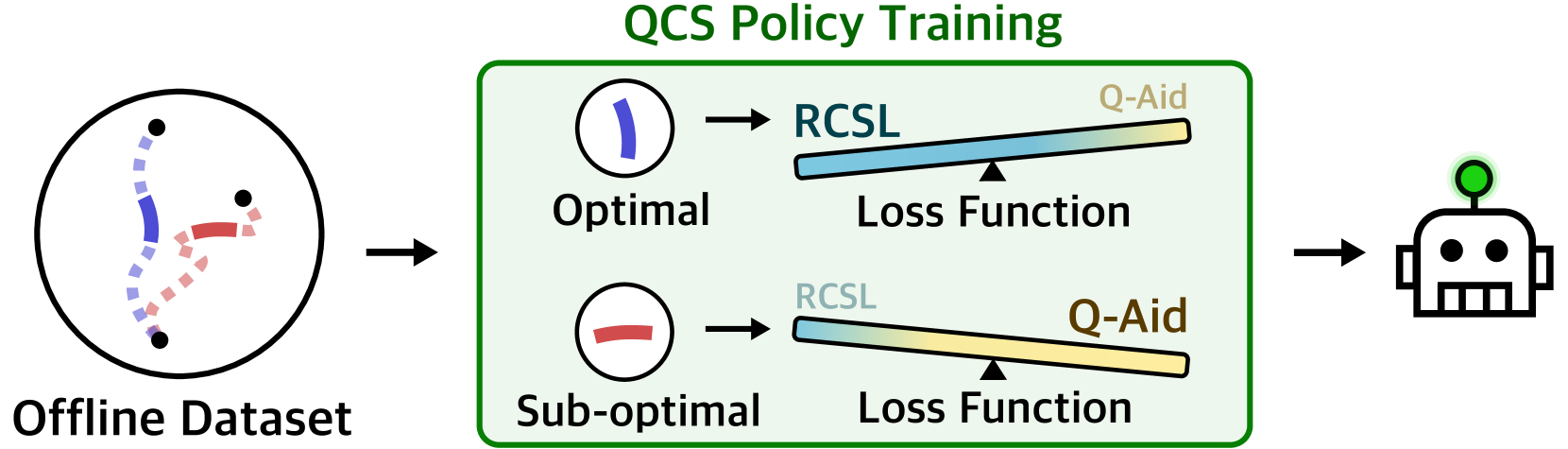
Adaptive Q-Aid for Conditional Supervised Learning in Offline Reinforcement Learning
Neural Information Processing Systems · 2024
QCS adaptively combines return-conditioned supervised learning with a Q-function — leaning on RCSL for optimal trajectories and on Q-aid for sub-optimal ones — to recover trajectory-stitching ability without sacrificing stability.