|
suyounglee424 [at] gmail [dot] com suyoung.lee [at] krafton [dot] com Welcome to my homepage. I currently work as an ML engineer at the Gameplay AI Team, Krafton. My current interest is building AI agents that can play games {like, with, against} humans.
Google Scholar / Github / CV / Thesis Slides |

|
|
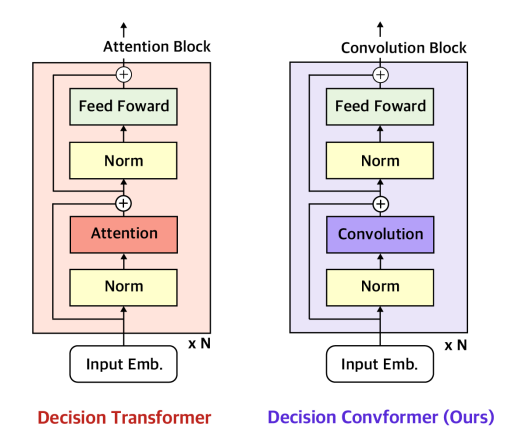
Jeonghye Kim, Suyoung Lee, Woojun Kim, and Youngchul Sung International Conference on Learning Representations (ICLR), 2024 as Spotlight presentation (366/7262= 5.0%) Foundation Models for Decision Making (FMDM) Workshop at NeurIPS, 2023. We propose Decision ConvFormer, a new decision-maker based on MetaFormer with three convolution filters for offline RL, which excels in decision-making by understanding local associations and has an enhanced generalization capability. |
|
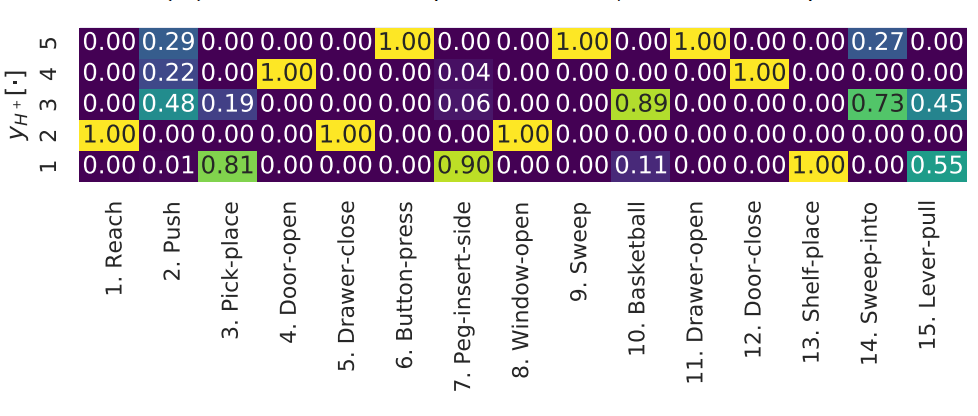
Suyoung Lee, Myungsik Cho, and Youngchul Sung Neural Information Processing Systems (NeurIPS), 2023. pdf / code We enhance the generalization capability of meta-reinforcement learning on tasks with non-parametric variability by decomposing the tasks into elementary subtasks and conducting virtual training. |
|
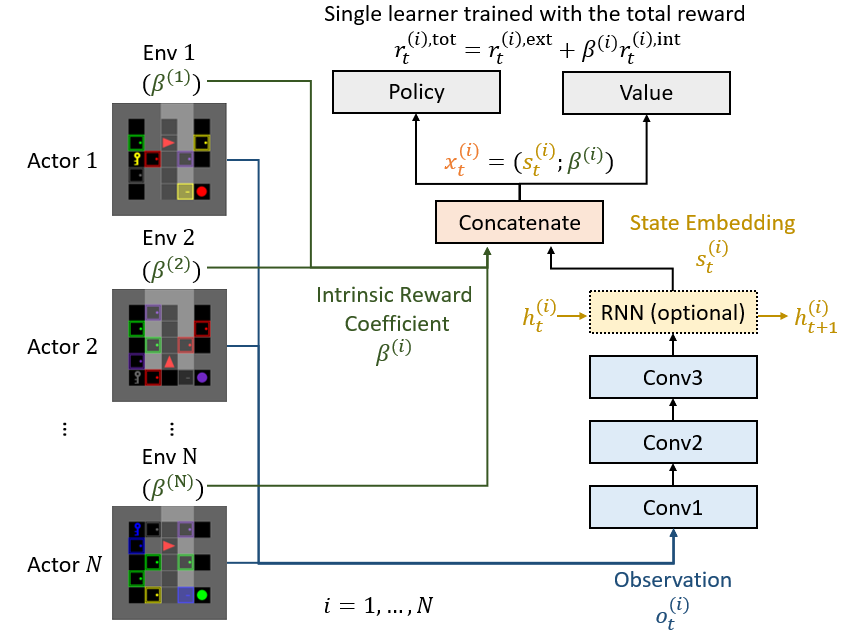
Suyoung Lee and Sae-Young Chung Decision Awareness in Reinforcement Learning Workshop at ICML, 2022. We propose an intrinsic reward coefficient adaptation scheme equipped with intrinsic motivation awareness and adjusts the intrinsic reward coefficient online to maximize the extrinsic return. |
|
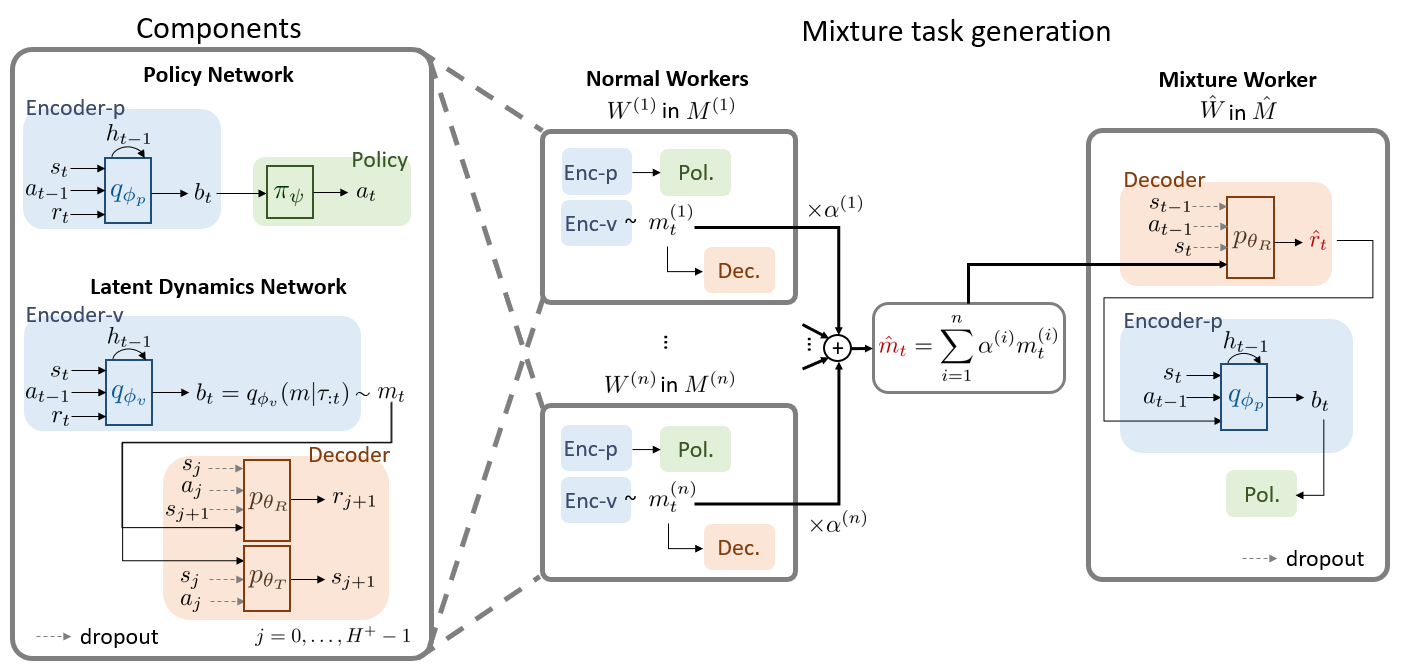
Suyoung Lee and Sae-Young Chung Neural Information Processing Systems (NeurIPS), 2021. pdf / code We train an RL agent with imaginary tasks generated from mixtures of learned latent dynamics to generalize to unseen test tasks. |
|
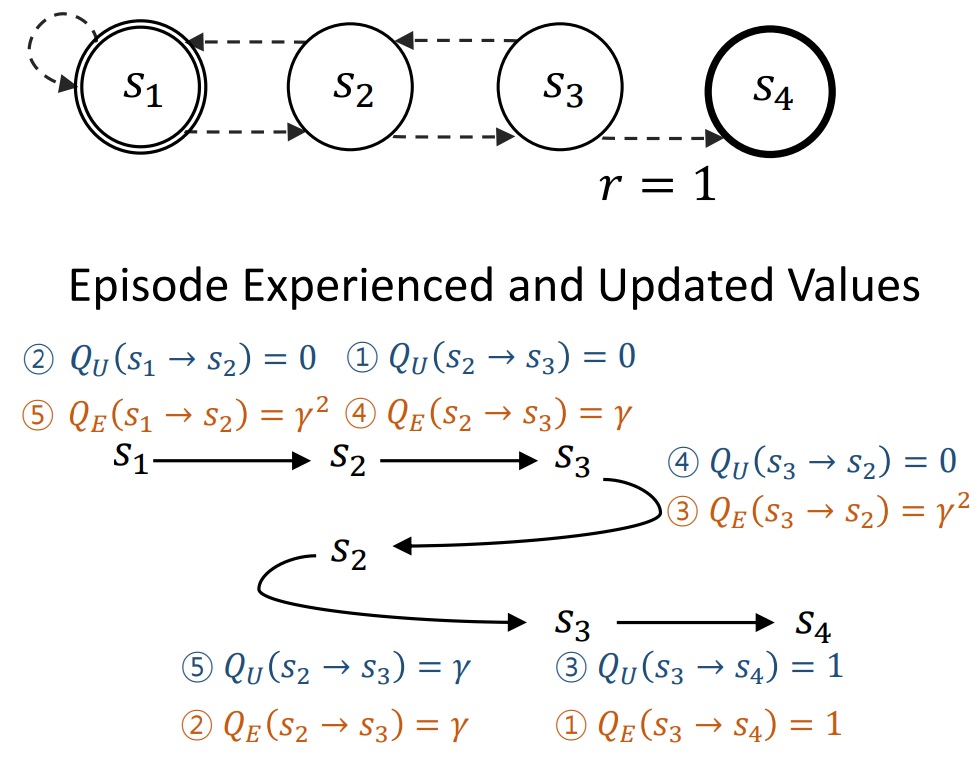
Suyoung Lee, Sungik Choi, and Sae-Young Chung Neural Information Processing Systems (NeurIPS), 2019. pdf / code A computationally efficient recursive deep reinforcement learning algorithm that allows sparse and delayed rewards to propagate directly through all transitions of the sampled episode. |
|
Outstanding Ph.D. Dissertation Award - Thesis: Meta-Reinforcement Learning with Imaginary Tasks, KAIST EE, 2024. Qualcomm-KAIST Innovation Awards 2018 - paper competition awards for graduate students, Qualcomm, 2018. Un Chong-Kwan Scholarship Award - for the achievement of excellence in the 2017 entrance examination, KAIST EE, 2017. |
|
2022~ 2024: Ph.D. in Electrical Engineering, KAIST, Daejeon, Korea (advisor: Prof. Youngchul Sung). 2019~2022: Ph.D. in Electrical Engineering, KAIST, Daejeon, Korea (advisor: Prof. Sae-Young Chung). 2017~2019: M.S. in Electrical Engineering, KAIST, Daejeon, Korea (advisor: Prof. Sae-Young Chung). 2012~2017: B.S. in Electrical Engineering, KAIST, Daejeon, Korea. 2010~2012: Hansung Science High School, Seoul, Korea. 2007~2009: Tashkent International School, Tashkent, Uzbekistan. |
|
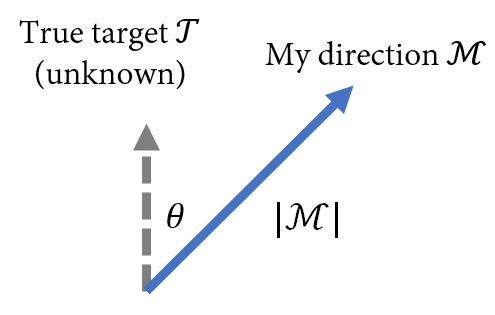
I view life as a meta-reinforcement learning task, reminiscent of the MuJoCo Ant-direction. Everyone has their own unique, albeit often obscured, optimal life direction T. The objective of life is to maximize the cumulative reward r=M·T, defined as the dot product of our chosen direction M (how we decide to live) and the unseen true direction T. I was fortunate to have guidance from two professors who instilled in me the importance of minimizing the angle ∣θ∣ and maximizing the magnitude ∣M∣. |
|
Website template from here. |